Vectorization
Dmitriy Selivanov
2017-07-05
文本分析工作流
大多数文本挖掘和自然语言建模使用 bag of words 或者 bag of n-grams 方法。即使它们很简单,这些模型通常在文本分类任务有较好的效果。虽然这些模型的理论很简单,构建高效率的 bag-of-words 模型需要面对很多技术上的问题。对于 R 来说,R 的在修改时复制(copy-on-modify)的特点,会影响到模型构建效率。
让我们来简单回顾文本分析工作流的常见步骤:
研究者从输入文本构建 document-term matrix (DTM) 或者 term-co-occurrence matrix (TCM)。或者说,第一步是构建一个映射,将词或者 n-gram 映射到一个向量空间(vector space)。
研究者拟合 DTM 模型,这些模型可以是文本分类模型,主题模型,相似性研究等等。拟合模型的过程包括调优和验证模型。
最后研究者将模型运用在新数据上。
在本文中,我们将会主要讨论第一个步骤。文本数据常需要大量的内存来储存,而文本向量却不需要,因为文本向量市稀疏矩阵。因为 R 的修改时复制的属性,交互式地构建一个 DTM 并不容易,构建一小部分集合的文档也需要花费很多时间。这涉及到将整个集合大文本读入到内存中,将它们处理成为一个独立的向量,这个步骤需要使用 2 到 4 倍文本容量的内存。
text2vec 包提供了一个比上述方法更好的解决方案来处理 document-term matrix。
让我们来用一个实际的例子来演示包的核心功能 - 情感分析。
text2vec 包提供了 movie_review 数据集,它包含 5000 个电影评论,每个评论被标记为正面或者负面。我们将会使用 data.table 包来预处理数据。
首先将数据分成两部分,训练集和测试集,我们将会展示怎么样在训练集和测试集上面进行同样的数据操作。
library(text2vec)
library(data.table)
data("movie_review")
setDT(movie_review)
setkey(movie_review, id)
set.seed(2016L)
all_ids = movie_review$id
train_ids = sample(all_ids, 4000)
test_ids = setdiff(all_ids, train_ids)
train = movie_review[J(train_ids)]
test = movie_review[J(test_ids)]向量化
为了在向量空间里面展示文档,我们首先需要生成多个字段(terms)到字段(term)的 IDS。我们把他们叫做字段而不是词(words),是因为他们可以是任意 n-gram 而不仅仅是单个词。我们将一个集合的文档表示为稀疏矩阵,每一行代表一个文档,每一列代表一个 term。可以用两种方法来处理文本,使用词汇表本身,或者使用 feature hashing。
基于词汇表的向量表
让我们先来生成一个基于词汇表的 DTM。我们从所有文档中收集独立的字段,使用 create_vocabulary() 将每一个词用一个独立的ID 来进行标记。
# 定义预处理函数以及 tokenization 函数
prep_fun = tolower
tok_fun = word_tokenizer
it_train = itoken(train$review,
preprocessor = prep_fun,
tokenizer = tok_fun,
ids = train$id,
progressbar = FALSE)
vocab = create_vocabulary(it_train)这里完成了什么?
- 使用
itoken()对 tokens 生成一个迭代器。所有包含create_前缀的函数都能处理这些迭代区。R 用户可能会觉得这类模型不是很常见,但是迭代器允许我们隐藏输入的大部分的细节,并以内存友好的方式来处理数据。 - 我们使用
create_vocabulary()函数构建一个词汇表。
或者我们能够生成一列 tokens,然后在后续的步骤中重用他们。列表里面的每个元素代表一个文档,每个元素为一个包含 tokens 的文本向量。
train_tokens = train$review %>%
prep_fun %>%
tok_fun
it_train = itoken(train_tokens,
ids = train$id,
# turn off progressbar because it won't look nice in rmd
progressbar = FALSE)
vocab = create_vocabulary(it_train)
vocab## Number of docs: 4000
## 0 stopwords: ...
## ngram_min = 1; ngram_max = 1
## Vocabulary:
## terms terms_counts doc_counts
## 1: overturned 1 1
## 2: disintegration 1 1
## 3: vachon 1 1
## 4: interfered 1 1
## 5: michonoku 1 1
## ---
## 35592: penises 2 2
## 35593: arabian 1 1
## 35594: personal 102 94
## 35595: end 921 743
## 35596: address 10 10注意到 text2vec 提供了一些 tokenizer 函数(见?tokenizers),这些函数是 base::gsub() 的简单接口,他们的速度不是很快,如果你需要更加智能或者更快速的包,可以使用 tokenizers。这个包可以满足绝大多数多使用需求。你还可以使用 stringi 包来写你自己多 tokenizer。
现在我们有了一个词汇表,我们接着来建立一个 document-term matrix。
vectorizer = vocab_vectorizer(vocab)
t1 = Sys.time()
dtm_train = create_dtm(it_train, vectorizer)
print(difftime(Sys.time(), t1, units = 'sec'))## Time difference of 0.8716209 secs现在我们有了一个 DTM,我们可以查看他的维度。
dim(dtm_train)## [1] 4000 35596identical(rownames(dtm_train), train$id)## [1] TRUE正如你所看到的,DTM 有 行,和文档数一致, 列,与独立的字段数一致。
现在我们准备拟合我们的第一个模型。这里我们将会使用 glmnet 包来拟合一个包含 L1 惩罚和 4 折交叉验证的模型。
library(glmnet)
NFOLDS = 4
t1 = Sys.time()
glmnet_classifier = cv.glmnet(x = dtm_train, y = train[['sentiment']],
family = 'binomial',
# L1 penalty
alpha = 1,
# interested in the area under ROC curve
type.measure = "auc",
# 5-fold cross-validation
nfolds = NFOLDS,
# high value is less accurate, but has faster training
thresh = 1e-3,
# again lower number of iterations for faster training
maxit = 1e3)
print(difftime(Sys.time(), t1, units = 'sec'))## Time difference of 2.747643 secsplot(glmnet_classifier)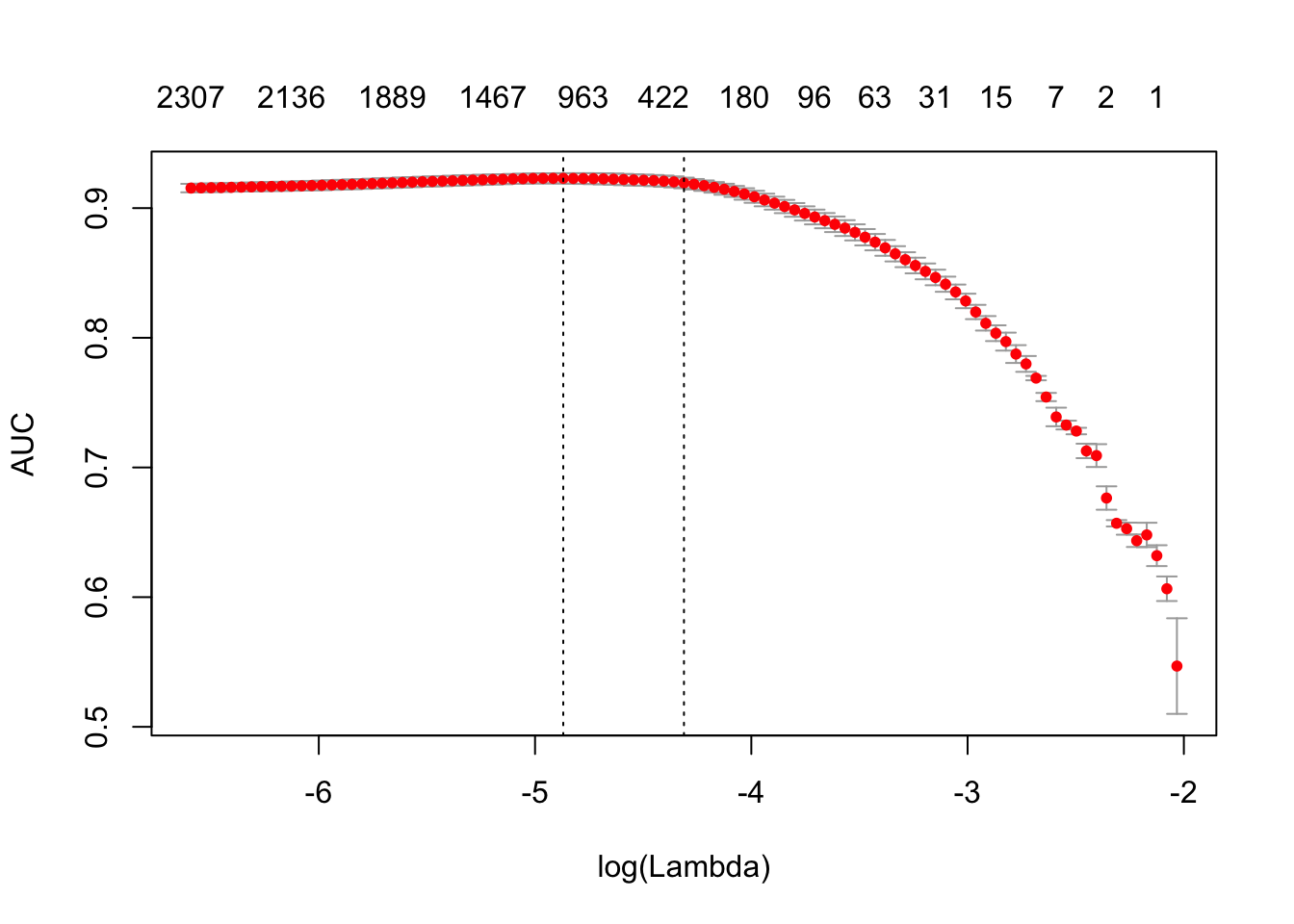
print(paste("max AUC =", round(max(glmnet_classifier$cvm), 4)))## [1] "max AUC = 0.923"现在我们成功地将我们的 DTM 拟合了一个模型,现在我们需要在我们的测试集上检查模型的性能。
注意到我们使用同样的函数来进行数据预处理和 tokenization。我们也冲用了同样的将字段转换为数字标记的 vectorizer 函数。
# Note that most text2vec functions are pipe friendly!
it_test = test$review %>%
prep_fun %>%
tok_fun %>%
itoken(ids = test$id,
# turn off progressbar because it won't look nice in rmd
progressbar = FALSE)
dtm_test = create_dtm(it_test, vectorizer)
preds = predict(glmnet_classifier, dtm_test, type = 'response')[,1]
glmnet:::auc(test$sentiment, preds)## [1] 0.916697正如我们看到的,测试集的结果和交叉检验的结果类似。
修剪词汇表
我们注意到模型的训练时间很长,我们能够通过修剪词汇表的方法来显著地提高模型的准确率。
比如,我们可以发现 “a”, “the”, “in”, “I”, “you”, “on” 这些词在几乎所有的文档里都出现了,他们不能够提供很多大有效信息,一般我们称这些词汇为 stop words。另一方面,词汇表中包含一些很稀有的项,它们只在很少大文档中出现。这些项也是无用的,因为我们没有关于它们的足够的统计信息。
在这里我们会移除预定义的停止词,一些常见的词以及一些很稀有的词。
stop_words = c("i", "me", "my", "myself", "we", "our", "ours", "ourselves", "you", "your", "yours")
t1 = Sys.time()
vocab = create_vocabulary(it_train, stopwords = stop_words)
print(difftime(Sys.time(), t1, units = 'sec'))## Time difference of 0.326699 secspruned_vocab = prune_vocabulary(vocab,
term_count_min = 10,
doc_proportion_max = 0.5,
doc_proportion_min = 0.001)
vectorizer = vocab_vectorizer(pruned_vocab)
# create dtm_train with new pruned vocabulary vectorizer
t1 = Sys.time()
dtm_train = create_dtm(it_train, vectorizer)
print(difftime(Sys.time(), t1, units = 'sec'))## Time difference of 0.6122341 secsdim(dtm_train)## [1] 4000 6585注意到新生成的 DTM 比原有 DTM 包含更少的列,一般地这能够获得更高的准确率以及更快的训练速度。
我们还需要使用同样的 vectorizer 为测试集生成 DTM。
dtm_test = create_dtm(it_test, vectorizer)
dim(dtm_test)## [1] 1000 6585N-grams
我们能够改进我们的模型吗?当然可以,我们需要使用 n-grams 而不是词。这里我们使用 2-grams:
t1 = Sys.time()
vocab = create_vocabulary(it_train, ngram = c(1L, 2L))
print(difftime(Sys.time(), t1, units = 'sec'))## Time difference of 1.246217 secsvocab = vocab %>% prune_vocabulary(term_count_min = 10,
doc_proportion_max = 0.5)
bigram_vectorizer = vocab_vectorizer(vocab)
dtm_train = create_dtm(it_train, bigram_vectorizer)
t1 = Sys.time()
glmnet_classifier = cv.glmnet(x = dtm_train, y = train[['sentiment']],
family = 'binomial',
alpha = 1,
type.measure = "auc",
nfolds = NFOLDS,
thresh = 1e-3,
maxit = 1e3)
print(difftime(Sys.time(), t1, units = 'sec'))## Time difference of 1.929552 secsplot(glmnet_classifier)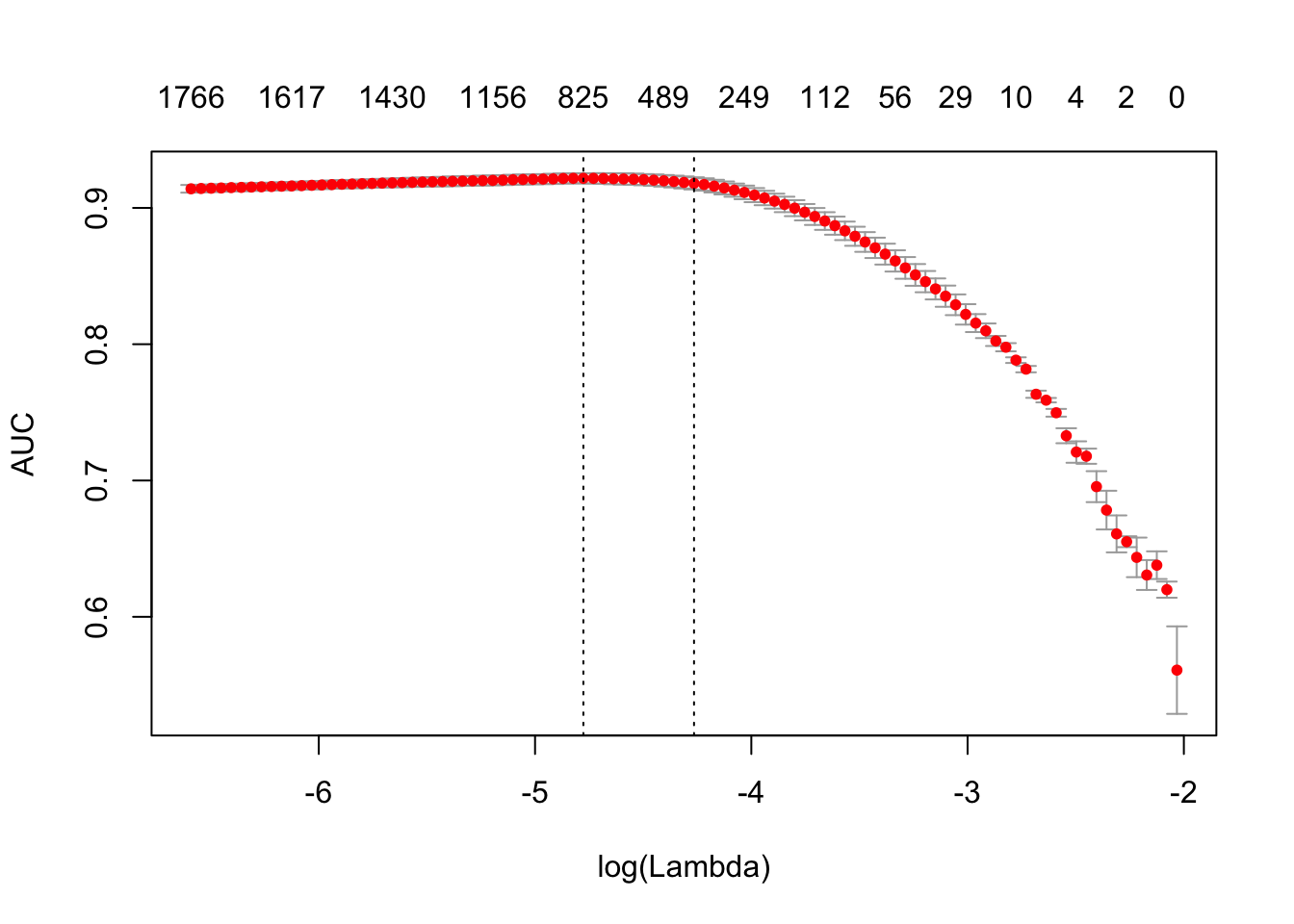
print(paste("max AUC =", round(max(glmnet_classifier$cvm), 4)))## [1] "max AUC = 0.9217"注意到使用 n-grams 对我们的模型有一定的提升,让我们来看看测试集的结果。
# apply vectorizer
dtm_test = create_dtm(it_test, bigram_vectorizer)
preds = predict(glmnet_classifier, dtm_test, type = 'response')[,1]
glmnet:::auc(test$sentiment, preds)## [1] 0.9268974读者可以对模型进行更进一步的调优。
Feature hashing
如果你对 Feature hashing 不熟悉,我推荐你从这篇 [Wikipedia 文章] (https://en.wikipedia.org/wiki/Feature_hashing) 来了解对应的信息,然后阅读 Yahoo!研究团队的论文。
这个方法的效率很高,因为我们不需要对关联数组进行检索。这个方法的另外一个好处是它内存友好,因为我们可以将任意数量的特征映射到一个稠密的空间。这个方法被 Yahoo! 推广,并被广泛运用在 Vowpal Wabbit.
这里是一个在 text2vec 中使用 feature hashing 的例子。
h_vectorizer = hash_vectorizer(hash_size = 2 ^ 14, ngram = c(1L, 2L))
t1 = Sys.time()
dtm_train = create_dtm(it_train, h_vectorizer)
print(difftime(Sys.time(), t1, units = 'sec'))## Time difference of 1.32215 secst1 = Sys.time()
glmnet_classifier = cv.glmnet(x = dtm_train, y = train[['sentiment']],
family = 'binomial',
alpha = 1,
type.measure = "auc",
nfolds = 5,
thresh = 1e-3,
maxit = 1e3)
print(difftime(Sys.time(), t1, units = 'sec'))## Time difference of 3.174371 secsplot(glmnet_classifier)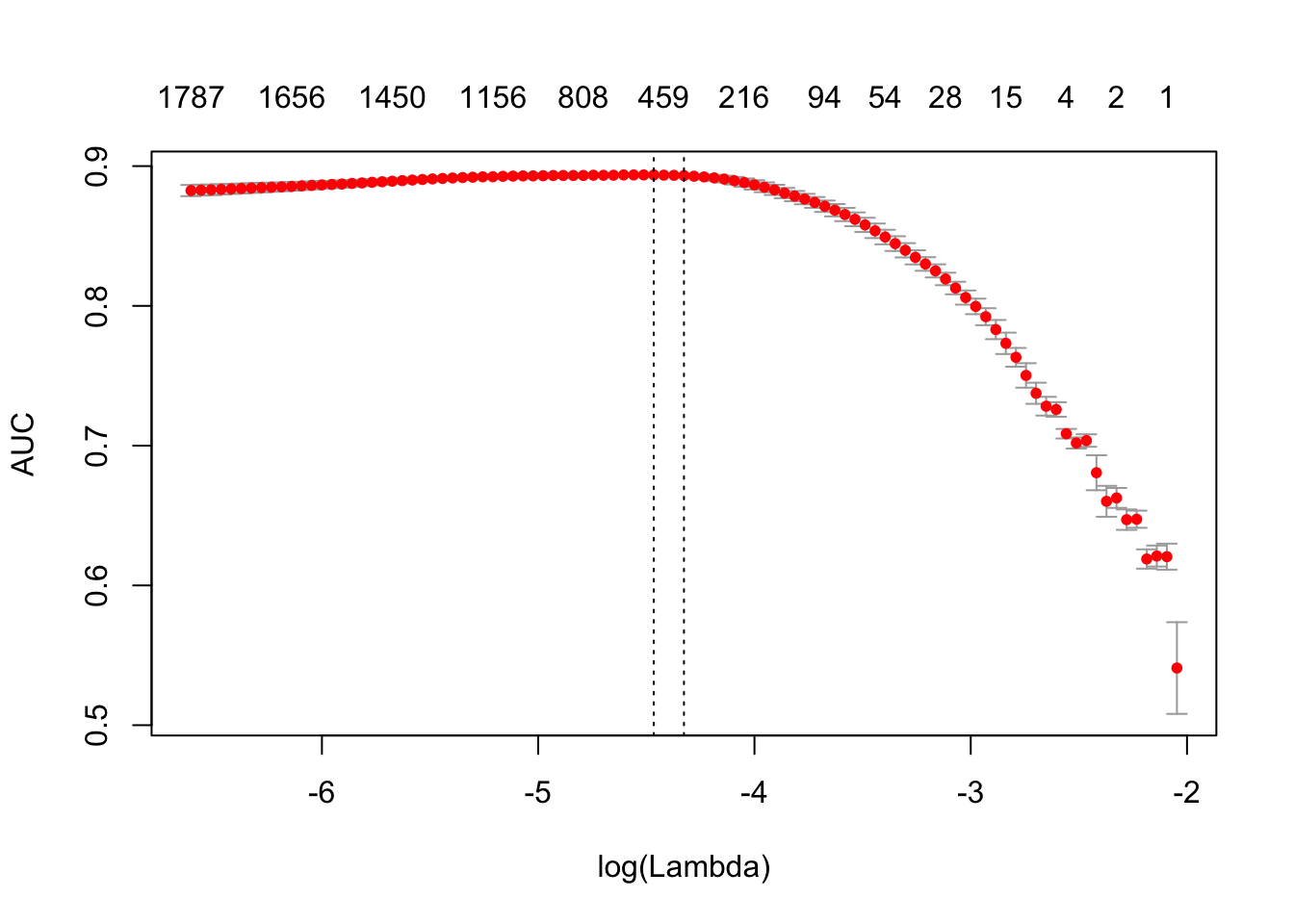
print(paste("max AUC =", round(max(glmnet_classifier$cvm), 4)))## [1] "max AUC = 0.8937"dtm_test = create_dtm(it_test, h_vectorizer)
preds = predict(glmnet_classifier, dtm_test , type = 'response')[, 1]
glmnet:::auc(test$sentiment, preds)## [1] 0.9036685正如你看到的,我们的 AUC 稍微差一些,但是 DTM 的训练时间有了明显的改善。
基本的变换
在进行分析之前,我们一般都会对 DTM 进行一定的变换。比如,不同文档的长度会有很大的差别,在这个例子中,使用标准化(normalization)将会十分有意义。
标准化
为了实现标准化,我们将 DTM 到将不同长度到文档调整到一个共同的尺度上。针对不同长度的文档,我们使用 L1 标准化,及将每一列的数值转换为和为 1 。
dtm_train_l1_norm = normalize(dtm_train, "l1")这个转换可以改进我们数据预处理的质量。
TF-IDF
另外一个流行的技术是 TF-IDF 转换。
我们可以将它运用在我们的 DTM 上,它不仅仅会标准化 DTM,提升针对某单个文档或者一类文档的字段的权重,降低常用字段的权重。
vocab = create_vocabulary(it_train)
vectorizer = vocab_vectorizer(vocab)
dtm_train = create_dtm(it_train, vectorizer)
# 定义模型
tfidf = TfIdf$new()
# 用训练数据拟合模型,并转换训练数据
dtm_train_tfidf = fit_transform(dtm_train, tfidf)
# tfidf 会被 fit_transform() 修改
# 将训练好的 tfidf 模型运用到测试数据上
dtm_test_tfidf = create_dtm(it_test, vectorizer) %>%
transform(tfidf)注意到这里我们第一次在 text2vec 使用模型对象。现在用户可以了解 text2vec 模型的一些重要的属性:
- 模型可以使用给定数据(训练集)来进行拟合,并将它运用到新的数据(测试集)上。
- 模型是可变的 一旦你将模型传递给
fit()或者fit_transform()函数,模型将会被修改。 - 一旦模型被拟合后,它可以使用
transform(new_data, fitted_model)方法被运用到新的数据上。
更多关于模型概述的细节以及模型的 API,可以在独立的 vignette 里面查看。
一旦我们拥有使用 tf-idf 重新调整过的 DTM,我们可以重新拟合我们的线性分类器。
t1 = Sys.time()
glmnet_classifier = cv.glmnet(x = dtm_train_tfidf, y = train[['sentiment']],
family = 'binomial',
alpha = 1,
type.measure = "auc",
nfolds = NFOLDS,
thresh = 1e-3,
maxit = 1e3)
print(difftime(Sys.time(), t1, units = 'sec'))## Time difference of 2.077677 secsplot(glmnet_classifier)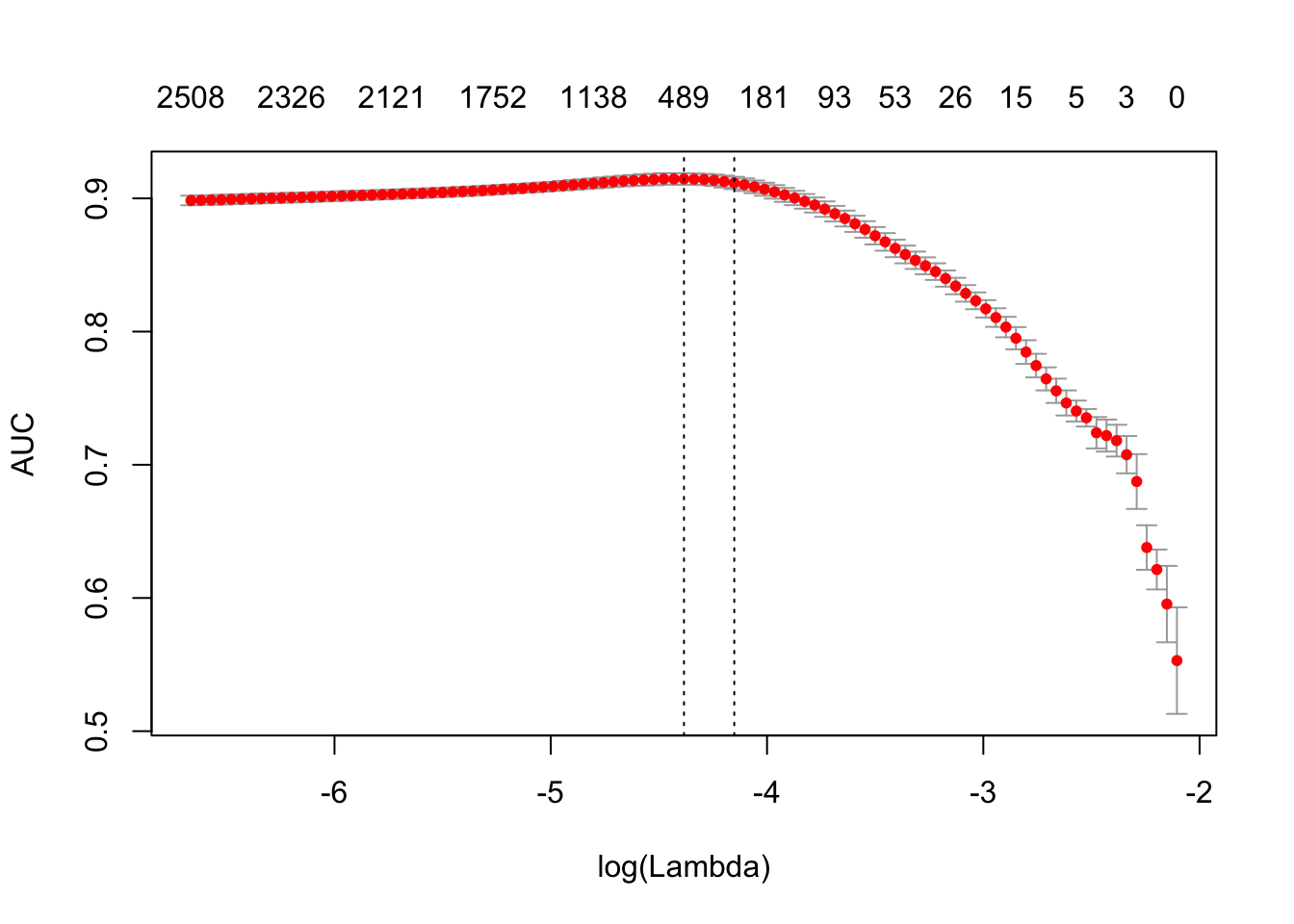
print(paste("max AUC =", round(max(glmnet_classifier$cvm), 4)))## [1] "max AUC = 0.9146"检查一下模型在测试集上的效果:
preds = predict(glmnet_classifier, dtm_test_tfidf, type = 'response')[,1]
glmnet:::auc(test$sentiment, preds)## [1] 0.9053246一般来说,tf-idf 转换能够显著地改善绝大多数任务的结果。